🔍 Looking for Remote Code Execution bugs in the Linux kernel
- 🎬 Introduction
- 💉 Injecting network packets — TUN/TAP
- 🚚 Collecting network coverage — KCOV
- 🏗 Integrating into syzkaller
- 🧰 About syzkaller
- 📖 Syscall descriptions
- 🧤 Adding a syscall for packet injection
- 🔎 Inspecting coverage #1
- 🗄 Describing packet structure
- 🔍 Inspecting coverage #2
- 🏷 Dealing with checksums
- 🥳 Getting first crashes
- 🔎 Inspecting coverage #3
- 🎁 Opening a TCP socket
- 🤝 Establishing a TCP connection
- 🕵 Avoiding ARP traffic
- 🚽 Adding IPv6 support
- ☝ Other notable things
- 🏆 Found bugs
- 🪠 Things to improve
- 🗃 Summary
- 📝 Afterword
🔍 Looking for Remote Code Execution bugs in the Linux kernel
How would an attacker remotely take over a personal Linux or Android device? Send a malicious link and get code execution through the browser? Or target a messenger or an email client? Well, how about sending a series of network packets and owning the kernel directly 😋
This article covers my experience with fuzzing the Linux kernel externally over the network. I’ll explain how I extended a kernel fuzzer called syzkaller for this purpose and show off the found bugs. The article also includes an introduction to syzkaller and its advanced feature — pseudo-syscalls.
Sadly, to find that one bug to take over the Internet — I failed. But I did manage to find a one-shot RCE in a non-public kernel flavor.
- 🎬 Introduction
- 💉 Injecting network packets — TUN/TAP
- 🚚 Collecting network coverage — KCOV
- 🏗 Integrating into syzkaller
- 🧰 About syzkaller
- 📖 Syscall descriptions
- 🧤 Adding a syscall for packet injection
- 🔎 Inspecting coverage #1
- 🗄 Describing packet structure
- 🔍 Inspecting coverage #2
- 🏷 Dealing with checksums
- 🥳 Getting first crashes
- 🔎 Inspecting coverage #3
- 🎁 Opening a TCP socket
- 🤝 Establishing a TCP connection
- 🕵 Avoiding ARP traffic
- 🚽 Adding IPv6 support
- ☝ Other notable things
- 🏆 Found bugs
- 🪠 Things to improve
- 🗃 Summary
- 📝 Afterword
⬅ Note the interactive table of contents on the left.
🎬 Introduction
🖼 Background
I’ll be calling remotely-triggerable bugs simply “remote” for the rest of the article.
Let’s start with a bit of background information on remotely-triggerable bugs, fuzzing, and syzkaller.
Keep an eye out for the side notes on the right ➡
Remote bugs. Whenever a Linux machine receives a packet over the network, it needs to understand what to do with it. For example, for a TCP packet, the machine needs to know to which application the packet should be delivered. This is done by the kernel: it parses the packet and deals with it accordingly. For the TCP packet, the kernel routes it to the application listening on the port specified inside the packet.
If there’s a bug in the kernel code that parses network packets, this bug can be triggered by a remote attacker. It can be as simple as sending a specially-crafted packet to the machine.
See A Guide to Kernel Exploitation: Attacking the Core for the exploit details.
Remote exploits. If a remote bug is a memory corruption, a skilled attacker can exploit it to make the kernel execute arbitrary code. And, thus, overtake the machine. There was at least one such Remote Code Execution bug with a public exploit: a buffer-overflow in SCTP discovered over a decade ago.
Of course, making a remote exploit requires finding a remotely-exploitable bug first. And that’s what I wanted to do.
Fuzzing. My approach to looking for such remote vulnerabilities was to use fuzzing.
Fuzzing is a way to find bugs in programs by feeding in random inputs. If the program crashes or otherwise misbehaves while processing an input, there is a bug. The kernel is a program, so it can be targeted by fuzzing too.
In case of fuzzing the network subsystem externally, the fuzzer would generate a random packet, somehow feed it into the kernel, and check if the kernel misbehaved. For example, crashed or printed a KASAN report. This would mean that the fuzzer has found a bug.
For brevity, I will skip describing how coverage-guided fuzzing works and detailing the specifics of kernel fuzzing. Be sure to check Ruffling the penguin! How to fuzz the Linux kernel to learn about these things.
syzkaller. For fuzzing, I wanted to use syzkaller — a production-grade coverage-guided kernel fuzzer developed by Google. syzkaller can fuzz many different kernels, but its main target is the Linux kernel.
Compared to a fuzzer made from scratch, syzkaller provides a ready-to-use framework and automates bug reporting. As a trade-off, you have to deal with syzkaller’s complexity: adding features requires learning about the inners of syzkaller’s architecture.
By the time I started working on this project, syzkaller already had basic support for fuzzing the network subsystem. But only the parts of code reachable locally over syscalls. And I wanted to target the code that parses packets that are received externally.
When I started this project, I already had experience with making bug-finding tools and running a ready-made USB fuzzer. However, I had never implemented a fuzzer myself. I also had no knowledge about syzkaller nor the inners of the Linux kernel network subsystem.
📈 Planned steps
After spending some time looking into syzkaller and the network subsystem, I came up with the following steps:
Injecting network packets. First, I wanted to figure out how to inject packets into the kernel. In such a way that the kernel would parse them just as normal externally-received packets. Simply sending packets to the machine could work for a custom fuzzer, but I needed an approach compatible with the syzkaller’s architecture.
Collecting coverage. Then, I needed to find a way of collecting code coverage from the kernel code that parses network packets. syzkaller is a coverage-guided fuzzer by design. It can work without relying on coverage, but this is terribly inefficient.
Integrating into syzkaller. Finally, I wanted to put the first two parts together and integrate into syzkaller.
This last part turned out to be the largest piece. It entailed a long process of finding places where the fuzzer gets stuck and dealing with them one-by-one.
Now, let’s look into each of these parts separately.
💉 Injecting network packets — TUN/TAP
I started with looking for a way to inject packets into the kernel.
As I wanted to use syzkaller, I was constrained in the approaches I could use.
Host to guest. First, the chosen approach had to work regardless of the environment used to run the kernel. syzkaller runs on QEMU, GCE (Google Cloud Engine), and physical devices. Thus, for example, sending packets to the guest kernel from the host wouldn’t work: there could be no host at all.
Just send. A possible approach would be to put the fuzzer and its target on the same network and let the fuzzer simply send packets to the target. This would work regardless of the used environment: you can put any kind of virtual and physical devices on the same network.
However, this approach poorly fitted with the syzkaller’s architecture. syzkaller is designed to have the fuzzer process running inside the VM that it fuzzes. This is because syzkaller was initially developed to fuzz system calls, and the only way to call them is within the VM. Code coverage is also collected within the running system, and synchronizing it with externally controlled inputs would be a pain.
Custom driver. Ideally, I needed a way to inject network packets from within the VM. At first, I considered writing a piece of kernel code that takes a packet from userspace and injects it into the kernel network layer. But then I thought: “Maybe such code already exists?”.
While I was googling and asking around, the TUN/TAP interface caught my attention.
🧅 About TUN/TAP
| « | TUN/TAP provides packet reception and transmission for userspace programs. It can be seen as a simple Point-to-Point or Ethernet device, which, instead of receiving packets from physical media, receives them from a userspace program and, instead of sending packets via physical media, writes them to the userspace program. |
|---|---|
| Universal TUN/TAP device driver, Linux kernel documentation |
This sounded exactly like what I needed.
TUN/TAP acts as a virtual Network Interface Card (NIC). Compared to a real NIC, instead of getting packets from the hardware, TUN/TAP gets them from a userspace app. Then, these packets are parsed by the kernel. In the same way, as if they had been received from the hardware.
OpenVPN. A widely-known user of TUN/TAP is OpenVPN.
Picture redrawn from IPSec and OpenVPN worked-out examples.

When OpenVPN is in use, the packets sent by userspace apps 1 are routed through a virtual TUN/TAP-managed interface 2.
These packets are then delivered to the OpenVPN app 3, which adds the necessary encryption and sends them out through a hardware-backed interface 4 5 6.
A reverse process happens for packets received back from the hardware.
Target. Sending packets through TUN/TAP would allow fuzzing the generic packet parsing code in the kernel but not the drivers for network cards. This fitted well within my goals: I was interested in remote bugs in the core network layer anyway. Such bugs would affect every Linux device, not only the devices that use a particular driver.
🍴 Employing TUN/TAP
After reading a few TUN/TAP tutorials, I figured out a way to use it for external network fuzzing.
Setup.
First, open /dev/tun and issue a few ioctls to set it up in the raw mode:
#define IFACE "syz_tun"
int tun = open("/dev/net/tun", O_RDWR | O_NONBLOCK);
struct ifreq ifr;
memset(&ifr, 0, sizeof(ifr));
// Specify the interface name:
strncpy(ifr.ifr_name, IFACE, IFNAMSIZ);
// Specify the raw TAP mode:
ifr.ifr_flags = IFF_TAP | IFF_NO_PI;
// Set the interface name and mode.
ioctl(tun, TUNSETIFF, &ifr);
IFF_TAP turns on the TAP mode, which makes the device operate on raw Ethernet frames instead of higher-level protocol frames.
IFF_NO_PI instructs the kernel to not prepend a protocol information header to packets delivered to userspace.
This header includes the IP version, which is duplicated in the packet anyway.
It also includes an indicator of whether the received packet fits within the provided buffer.
This indicator doesn’t have much use for fuzzing.
Then, assign an IP and a MAC address to this interface:
TUN/TAP Demystified shows other ways to set up routing.
#define LOCAL_MAC "aa:aa:aa:aa:aa:aa"
#define LOCAL_IPV4 "172.20.20.170"
// Assign MAC and IP addresses.
execute_command("ip link set dev %s address %s", IFACE, LOCAL_MAC);
execute_command("ip addr add %s/24 dev %s", LOCAL_IPV4, IFACE);
Here, execute_command executes command-line commands.
Just like system but with printf-like arguments.
And finally, activate the interface:
// Activate the interface.
execute_command("ip link set %s up", IFACE);
Usage.
Now, you can write arbitrary Ethernet frames to /dev/tun:
// Write a packet into TUN/TAP.
write(tun, frame, length);
These frames would be handled by the kernel network subsystem in the same way as if they had been sent externally. Note that these frames should contain the same destination MAC and IP addresses as the addresses assigned to the interface. Otherwise, the frames would be rejected by the interface.
You can also use read(tun, ...) to receive back responses.
Done. And that’s it! This approach could already be used to write a custom fuzzer. Generate random packets with proper MAC and IP addresses, feed them into TUN/TAP, and let the kernel process them.
However, I wanted to use syzkaller, and thus I needed to integrate TUN/TAP into it.
But first, let’s look into collecting code coverage. This is a piece required to make full use of syzkaller.
🚚 Collecting network coverage — KCOV
Once again, check out Ruffling the penguin! How to fuzz the Linux kernel for details on coverage-guided fuzzing.
syzkaller relies on code coverage to guide its input generation algorithm.
To enable this guidance for generating network packets, I needed to find a way of collecting coverage from the kernel code that parses these packets. syzkaller uses KCOV for collecting coverage when it fuzzes syscalls, and I hoped that I could use it for my case as well.
📦 About KCOV
KCOV is a Linux kernel subsystem intended for code coverage collection. It was specifically developed for syzkaller with fuzzing application in mind.
See details and examples in KCOV’s documentation.
Internals.
KCOV consists of two parts: the instrumentation part implemented in the compiler and the runtime part implemented in the kernel.
When KCOV is enabled, the compiler inserts a callback into each basic block when building the kernel.
In turn, the runtime part implements these callbacks to record the addresses of executed basic blocks.
These addresses are then exposed via /sys/kernel/debug/kcov.
Note that KCOV doesn’t collect coverage from all running kernel tasks at once. It only collects coverage from the kernel code executing in the context of a single user process, the process that owns the KCOV instance. This allows syzkaller to extract coverage only from the syscalls that belong to a single fuzzing input. Otherwise, collecting coverage from the whole kernel results in too much noise. This also doesn’t work if multiple fuzzing processes work in parallel on the same kernel.

Usage. To use KCOV for syscall coverage collection:
-
Enable
CONFIG_KCOVin the kernel config and rebuild the kernel. -
Set up a KCOV instance for the current process:
int fd = open("/sys/kernel/debug/kcov", ...);
unsigned long *cover = mmap(NULL, ..., fd, 0);
ioctl(fd, KCOV_ENABLE, ...);
Now, this process can start calling syscalls, and the kernel will be saving the corresponding code coverage into cover.
📬 Employing KCOV
Unfortunately, I couldn’t directly use KCOV to collect coverage from the packet parsing code.
Interrupts.
Even though packets were injected from a userspace app, TUN/TAP didn’t handle them in the app context.
Instead, it queued them into a backlog and let the kernel process them in the NET_RX_SOFTIQ software interrupt.

Nowadays, KCOV can collect coverage from software interrupts via remote coverage.
As an interrupt might be handled in any kernel task, including a one lacking the userspace context, KCOV didn’t collect coverage from interrupts handlers.
That was unfortunate. Extending KCOV to collect coverage from software interrupts looked hard.
Instead, I decided to explore a different approach.
Hacking TUN/TAP. I patched the TUN/TAP code to parse packets on the spot:
The code in tun.c changed since when this patch was written, but the overall concept still stands.
diff --git a/drivers/net/tun.c b/drivers/net/tun.c
index a3ac8636f3ba9..a569e61bc1d9e 100644
--- a/drivers/net/tun.c
+++ b/drivers/net/tun.c
@@ -1286,7 +1286,13 @@ static ssize_t tun_get_user(struct tun_struct *tun, ...
skb_probe_transport_header(skb, 0);
rxhash = skb_get_hash(skb);
+#ifndef CONFIG_4KSTACKS
+ local_bh_disable();
+ netif_receive_skb(skb);
+ local_bh_enable();
+#else
netif_rx_ni(skb);
+#endif
stats = get_cpu_ptr(tun->pcpu_stats);
u64_stats_update_begin(&stats->syncp);
The patch modified the TUN/TAP function tun_get_user(), which handles packets passed from userspace.
The change made this function process packets immediately via netif_receive_skb() instead of putting them into the backlog via netif_rx_ni()->enqueue_to_backlog().
Processing packets on the spot extends the potential stack depth that can be reached, so this is only done when small stacks aren’t enabled via CONFIG_4KSTACKS.
With this patch, whenever a packet was sent through TUN/TAP, it was parsed in the context of the process that did the sending. And this enabled KCOV to collect coverage from the packet parsing code. Great!

Upstreaming. When I posted this patch on the mailing list, I received an unexpected response from Eric Dumazet — one of the network subsystem maintainers. Turned out, this patch was already suggested before, as it improved the TUN/TAP throughput. This was handy, as this added an incentive for upstream maintainers to take the patch.
Luckily, the patch was merged into the next Linux kernel release 🎉
🏗 Integrating into syzkaller
Perfect, at this point, I both had a way to inject network packets into the kernel and a way to collect coverage from the packet parsing code. Now I had to integrate these parts into syzkaller and also add support for generating properly structured network packets.
🧰 About syzkaller
Let’s start with a brief introduction to syzkaller.
Picture drawn based on How syzkaller works.

syzkaller is a coverage-guided kernel fuzzer that targets system calls.
Kernel fuzzer. syzkaller fuzzes OS kernels. It can handle a number of different kernels, but the most advanced support is for Linux and *BSDs. Adding support for new kernels is possible but requires significant engineering work.
Targets system calls. The Linux kernel has many interfaces that can be fuzzed. This includes internal APIs and external protocols like network and USB. syzkaller targets syscalls.
Nowadays, syzkaller can also fuzz a few external protocols. The network was the first one to be integrated. And this is what I describe in this article.
Requires descriptions. syzkaller needs descriptions of kernel interfaces to know which syscalls exist and what kind of arguments they accept. These descriptions are written manually by syzkaller developers.
Executes programs.
syzkaller executes syscalls in sequences called programs.
Programs are randomly generated based on the mentioned descriptions.
The syscalls in a program are usually related to each other.
For example, open() followed by a write() into the opened file.
Collects corpus. syzkaller keeps a list of programs it considers “interesting.” This list is called a corpus. Whenever a newly generated program looks “interesting,” syzkaller adds it to the corpus.
Mutates programs. Besides generating new programs from scratch, syzkaller can take one from the corpus and mutate it. Mutations include inserting and removing syscalls and changing their arguments. Mutated programs that syzkaller finds “interesting” are added to the corpus as well.
Coverage-guided. syzkaller decides whether a program is “interesting” based on the code coverage it gives. Programs that trigger new code paths in the kernel are added to the corpus. The rest are discarded. On Linux, syzkaller uses KCOV to collect coverage.
Detects crashes. syzkaller monitors the kernel log and looks for crash reports. It works best when coupled with dynamic bug-finding tools like KASAN or other Sanitizers.
Automated. syzkaller is highly automated. It manages the machines it uses for fuzzing: boots them, starts fuzzing processes, monitors logs for crashes, and restarts the machines when needed. syzkaller also reproduces crashes: it replays the programs executed before a crash and finds the one that is responsible.
Enables syzbot. syzkaller is integrated with syzbot. syzbot is a system that continuously fuzzes many different kernel flavors with various bug detectors and automatically sends bug reports to the kernel developers.
For more details about syzkaller, listen to the talk by Dmitry Vyukov syzkaller: adventures in continuous coverage-guided kernel fuzzing (video) from BlueHatIL 2020. For a story of finding and exploiting a security bug with syzkaller, check out my article Exploiting the Linux kernel via packet sockets in the Project Zero blog. There are also a few other resources listed in syzkaller documentation.
📖 Syscall descriptions
As I mentioned, syzkaller relies on manually-written syscall descriptions. The descriptions are written in a special declarative language called syzlang. The way to add support for fuzzing another kernel subsystem is writing descriptions of syscalls that are used to interface with this subsystem.
I won’t give a comprehensive guide to syzlang syntax, but let’s take a look at this excerpt from the socket-related descriptions:
See how syzlang syntax is highlighted? I implemented this myself 😊
resource sock[fd]
resource sock_in[sock]
resource sock_tcp[sock_in]
type sock_port int16be[20000:20004]
ipv4_addr [
rand_addr int32be[0x64010100:0x64010102]
empty const[0x0, int32be]
loopback const[0x7f000001, int32be]
] [size[4]]
sockaddr_in {
family const[AF_INET, int16]
port sock_port
addr ipv4_addr
} [size[16]]
socket$inet_tcp(domain const[AF_INET], type const[SOCK_STREAM],
proto const[0]) sock_tcp
bind$inet(fd sock_in, addr ptr[in, sockaddr_in], addrlen len[addr])
listen(fd sock, backlog int32)
Let me walk you through this excerpt part by part and introduce a few core syzlang features.
🔔 Syscalls
The excerpt describes three syscalls: socket$inet_tcp, which creates a TCP socket, bind$inet, which binds it to an address or a port, and listen, which puts the socket into the listening state.
Arguments. The descriptions specify what arguments these syscalls accept:
socket$inet_tcp(domain const[AF_INET], type const[SOCK_STREAM],
proto const[0]) sock_tcp
bind$inet(fd sock_in, addr ptr[in, sockaddr_in], addrlen len[addr])
listen(fd sock, backlog int32)
socket$inet_tcp accepts three constants;
bind$inet — an IPv4 socket file descriptor, a pointer to a sockaddr_in structure, and the length of that structure;
and listen — a socket file descriptor and an integer.
Variants.
The $ in syscall names is used to differentiate between variants of the same syscall.
For example, socket can be used to create many types of sockets.
syzkaller defines variants for a few common socket types like TCP and UDP:
socket$inet_tcp(domain const[AF_INET], type const[SOCK_STREAM],
proto const[0]) sock_tcp
socket$inet_udp(domain const[AF_INET], type const[SOCK_DGRAM],
proto const[0]) sock_udp
And there are also generic variants covering socket types that don’t yet have dedicated descriptions:
socket(domain flags[socket_domain], type flags[socket_type],
proto int32) sock
socket$inet(domain const[AF_INET], type flags[socket_type],
proto int32) sock_in
socket_domain = AF_UNIX, AF_INET, AF_INET6, AF_NETLINK, ...
socket_type = SOCK_STREAM, SOCK_DGRAM, SOCK_RAW, SOCK_RDM, ...
Here, socket_domain and socket_type define lists of values from which syzkaller chooses when generating the value for the corresponding flags argument.
All these variants rely on the same Linux socket syscall, but syzkaller uses different generation rules for their arguments.
⛏ Resources
For connecting related syscalls, syzkaller uses resources.
For example, socket$inet returns a sock_in resource, and bind$inet accepts this resource as an argument:
socket$inet(domain const[AF_INET], type flags[socket_type],
proto int32) sock_in
bind$inet(fd sock_in, addr ptr[in, sockaddr_in], addrlen len[addr])
This way, syzkaller knows to pass the return value of socket$inet to bind$inet in generated programs.
Inheritance. The excerpt defines three socket-related resource types, which are inherited one from another:
resource sock[fd]
resource sock_in[sock]
resource sock_tcp[sock_in]
When generating a program, syzkaller is more likely to use a resource of the type specified in the syscall definition. But it can also use a resource whose type is a parent or a child of the specified type.
Typically, inherited resource types are returned by different variants of the same syscall:
socket(...) sock
socket$inet(...) sock_in
socket$inet_tcp(...) sock_tcp
Specifications. Not all socket-related syscalls are defined to operate on all inherited resource types.
Take a look at the syscall definitions in the excerpt:
socket$inet_tcp(...) sock_tcp
bind$inet(fd sock_in, ...)
listen(fd sock, ...)
These are the most specific definitions of these syscalls.
socket$inet_tcp returns a TCP socket, bind$inet works with any IPv4 socket, and listen accepts any type of socket at all.
There are no definitions for the more specific bind$inet_tcp or listen$inet.
Theoretically, you could define bind$inet_tcp and bind$inet_udp syscalls that accept sock_tcp and sock_udp resources accordingly.
However, this has little practical sense.
Both syscalls would have the same second and third arguments, as the bind syscall has the same interface for TCP and UDP.
The generic bind$inet works just as well.
📇 Types
syzlang has over a dozen types used for syscall arguments and structure fields.
Most of them can be intuitively understood: const specifies a constant, int32 — a 4-byte integer, flags works as either a combination of bitwise flags or as an enum option, and len refers to the length of another field.
Pointers.
Let’s, however, take a closer look at ptr, which denotes a pointer.
First, a pointer type contains information about the type of object it points to.
For example, the mentioned bind$inet syscall accepts a pointer to the sockaddr_in structure as its second argument:
bind$inet(fd sock_in, addr ptr[in, sockaddr_in], addrlen len[addr])
Data-flow. Besides that, a pointer type contains the data-flow direction. This direction shows whether the syscall is expected to read data from the object or to write data into it.
In the case of bind$inet, the in keyword means that bind reads data from sockaddr_in.
Thus, syzkaller fills in the struct’s fields before executing this syscall.
Out pointers.
In turn, the out keyword means that the syscall is expected to write data into the structure.
For example, the second argument of accept$inet is marked as out, as accept stores the information about the connected peer there:
accept$inet(fd sock_in, peer ptr[out, sockaddr_in, opt],
peerlen ptr[inout, len[peer, int32]]) sock_in
opt in ptr[out, sockaddr_in, opt] means that the pointer is optional.
In this case, syzkaller sometimes skips providing this argument.
out pointers are particularly useful when syscall returns resources through structure fields.
syzkaller then knows to pass these resources to subsequent syscalls.
However, for accept$inet, sockaddr_in contains no resources.
Thus, the out marking won’t produce any effect except syzkaller not filling in the fields before executing the syscall.
However, if, say, sock_port were defined as a resource, syzkaller would thus know to reuse the returned port in syscalls following accept$inet in a program.
There are also inout pointers, which are used when data is both read and written by a syscall.
And there’s also a way to specify per-field data-flow direction in structures; see syzlang documentation for details.
🧱 Structures and unions
Structures.
Now, let’s take a closer look at the definition of the sockaddr_in structure:
sockaddr_in {
family const[AF_INET, int16]
port sock_port
addr ipv4_addr
} [size[16]]
This structure has three fields whose purposes are self-explanatory.
The size[16] annotation means that the structure will be padded with zeroes to reach 16 bytes in size.
As sock_port is used in other places besides sockaddr_in, it’s defined as a standalone type:
type sock_port int16be[20000:20004]
The be suffix in int32be means that the described integer is Big-Endian.
20000:20004 specifies an inclusive range of values that this integer can take.
syzkaller thus limits the number of distinct port values to 5. I’ll explain this limitation later in the article.
Unions.
In turn, ipv4_addr is defined as a union of a few IPv4 addresses:
ipv4_addr [
# Random public addresses 100.1.1.[0-2]:
rand_addr int32be[0x64010100:0x64010102]
# 0.0.0.0:
empty const[0x0, int32be]
# 127.0.0.1:
loopback const[0x7f000001, int32be]
] [size[4]]
A few options are hidden for consiceness. Click the switch to see them.
When generating an IPv4 address, syzkaller chooses one of the options from this union.
Binding a socket to different types of IP addresses puts it into different states. This is useful for fuzzing.
These are just the few main features of syzlang. See syzlang documentation for more details.
💾 Programs
When fuzzing, syzkaller generate programs based on the syzlang descriptions. A program is a random sequence of syscalls possibly connected via resources. When generating this sequence, syzkaller fills in syscall arguments with random values corresponding to their types.
Example. Here’s a program generated based on the network descriptions that I showed:
r0 = socket$inet_tcp(0x2, 0x1, 0x0)
bind$inet(r0, &(0x7f0000001000)={0x2, 0x0, @empty=0x0}, 0x10)
listen(r0, 0x5)
This program consists of three syscalls in a logical sequence.
socket$inet_tcp creates a TCP socket, bind$inet binds it to a port, and listen puts it into the listening state.
The syscalls are connected via the resource r0.
As you can see, syzkaller generated concrete values for each argument and structure field.
0x7f0000001000 denotes that the sockaddr_in structure is put at offset 0x1000 within the buffer intended for syscall arguments.
The values in {} are the fields of this structure.
0x0 used for the port stands for 20000: the value specifies the offset from the lower range bound.
Fuzzing process. In a loop, syzkaller keeps generating programs and executing them. In parallel, it’s monitoring the kernel log for crashes. A simple program like the one above is unlikely to crash the kernel, but a more complicated one might.
🧤 Adding a syscall for packet injection
So I needed to add syzlang descriptions for fuzzing the kernel over TUN/TAP.
Describe ioctls.
One option would be to simply add descriptions for the TUN/TAP ioctls.
Unfortunately, this would lead to mostly fuzzing the TUN/TAP code itself.
syzkaller would be mutating all of the arguments of these ioctls and putting them in weird orders.
This would have a low chance of setting up /dev/tun in the raw TAP mode, which was needed for packet injection.
Proper support. Instead, I needed to make syzkaller initialize TUN/TAP and then feed in generated packets.
👽 Pseudo-syscalls
This is where a useful syzkaller feature came in — pseudo-syscalls.
A pseudo-syscall is a way to bundle together a sequence of syscalls or other arbitrary logic.
Example.
Let’s take a look at the syz_opev_dev$loop pseudo-syscall for opening loop device files.
syzkaller defines several pseudo-syscalls besides syz_open_dev; they all are easily recognized by the syz_ prefix.
Any pseudo-syscall has two parts: a syzlang description and a C implementation.
Description.
In syzlang, syz_opev_dev$loop is defined with three arguments:
syz_open_dev$loop(dev ptr[in, string["/dev/loop#"]],
id intptr, flags flags[open_flags]) fd_loop
dev is a template of the device name with the device ID missing, id is the device ID, and flags are the flags for the open syscall.
Implementation.
In its C implementation, syz_opev_dev replaces the # character in the device name with the provided ID and opens the device file with the provided flags:
// Pseudo-code.
int syz_open_dev(device, id, flags) {
device = device.replace("#", string(id));
return open(device, flags);
}
syz_opev_dev$loop is just one of the many $ variants of syz_open_dev.
All variants share the same C implementation.
This implementation is defined in syz-executor.
Mutations.
From the point of view of syzkaller’s program mutator, syz_open_dev$loop is just another syscall.
Thus, when fuzzing, syzkaller mutates syzlang-defined arguments passed to this pseudo-syscall.
At the same time, syzkaller doesn’t change the logic of the pseudo-syscall’s C implementation.
Program.
Here’s an example of a program that uses syz_open_dev$loop:
r0 = syz_open_dev$loop(&(0x7f0000000140)='/dev/loop#\x00', 0x0, 0x1)
ioctl$LOOP_SET_DIRECT_IO(r0, 0x4c05, 0x0)
This is actually a reproducer for a bug syzkaller found in the loop device code.
Using pseudo-syscalls is discouraged, but they applied well to my network fuzzing use case.
🧄 Pseudo-syscall for TUN/TAP
There were two parts to injecting a packet through TUN/TAP:
- Set up a new interface in the raw TAP mode.
- Send the packet through this interface by writing it into the TUN/TAP file.
To integrate these parts into syzkaller, I could add a dedicated pseudo-syscall for each of them. However, it wouldn’t make sense to execute the first part multiple times: I only needed the interface to be set up once.
TUN/TAP setup. So instead, I made syzkaller execute the first part globally when it starts:
static int tunfd = -1;
// This function is indirectly called from syz-executor's main().
static void initialize_tun(void)
{
tunfd = open("/dev/net/tun", O_RDWR | O_NONBLOCK);
// Call the TUNSETIFF ioctl and do other TUN/TAP setup here.
}
Specifically, this is done in syz-executor, when it starts.
Pseudo-syscall.
For the second part, I created a new pseudo-syscall called syz_emit_ethernet.
Its arguments are a packet and its length.
In its C implementation, syz_emit_ethernet writes the packet into the globally opened /dev/tun:
This pseudo-syscall has a third argument that has to do with fragmentation. Not shown here for simplicity.
static long syz_emit_ethernet(volatile long a0, volatile long a1)
{
uint32 length = a0;
char *data = (char *)a1;
return write(tunfd, data, length);
}
Note that I couldn’t define a write$tun syscall that accepts tunfd in syzlang: tunfd is not a part of syzlang descriptions; it exists only in syz-executor’s C implementation.
And for the syzlang counter-part of syz_emit_ethernet, I started with a simple one that uses random data for the packet:
syz_emit_ethernet(len len[packet], packet ptr[in, array[int8]])
array[int8] describes an array of random length with random data.
This setup allowed syzkaller to mutate the packet but not corrupt the injection process itself.
Done. These were all the changes required to start fuzzing the network externally. Using random data for network packets wouldn’t probably allow the fuzzer to go deep: the sanity checks would fail. But this was a start.
These changes were exactly what I added in the first syzkaller pull request for external network fuzzing.
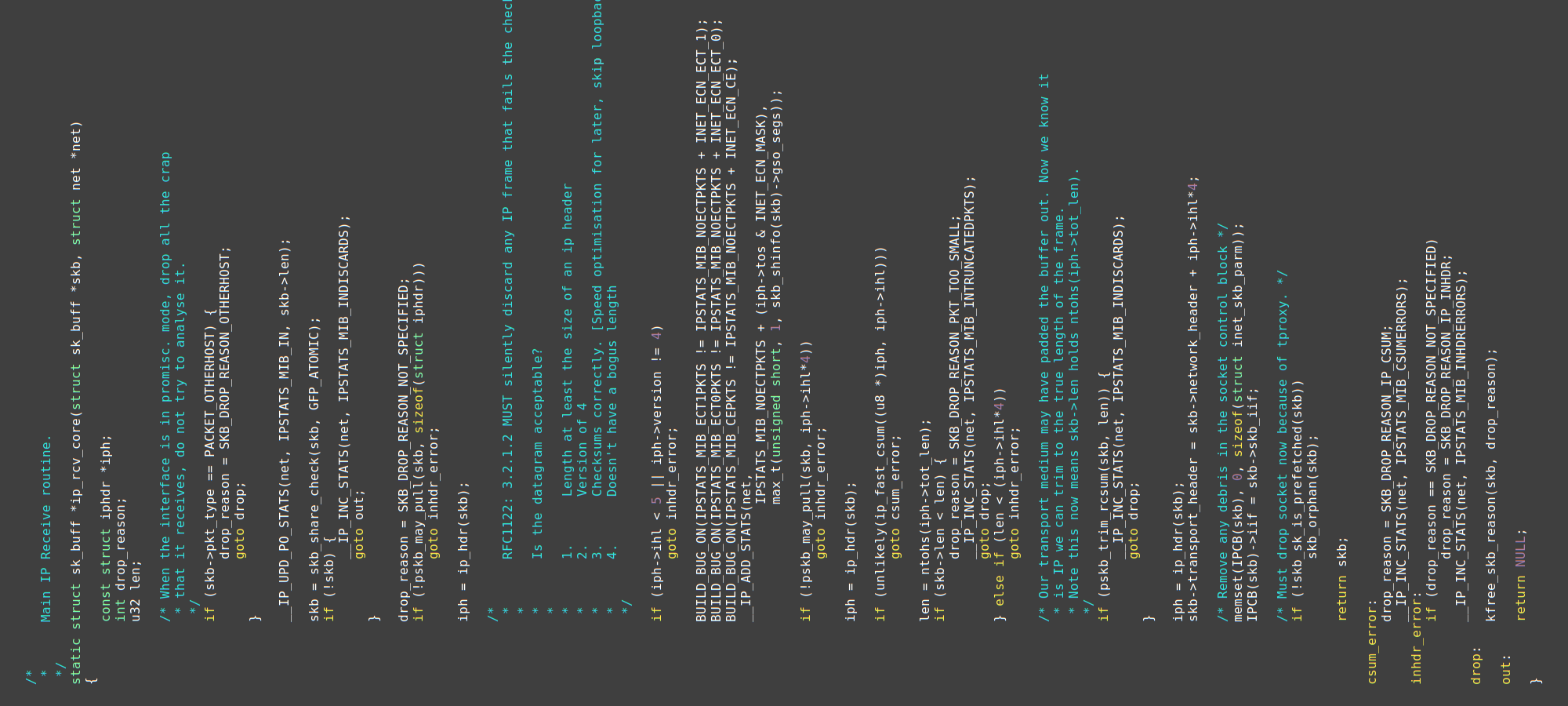
🔎 Inspecting coverage #1
Finally, I reached the point of starting the fuzzer for the first time.
Coverage. As I previously changed TUN/TAP to process injected packets on the spot, code coverage was being collected naturally via KCOV. No additional syzkaller changes were required.
First run.
After a few minutes of running with only the syz_emit_ethernet syscall enabled, I checked syzkaller’s code coverage report.
There, I saw that the fuzzer got stuck in ip_rcv_core() — the function that processes received IP packets:
All coverage reports in the article were generated on a newer kernel than the one I was using. Nevertheless, the described concepts stand.


Bold black lines correspond to covered basic blocks and red lines — to non-covered ones.
You can see that the last covered block in the function’s prologue is the if (!skb) check.
Since __IP_INC_STATS() is not covered, the !skb check succeeded.
Looking further into the function, you can see that the iph->ihl and version checks are not covered.
Thus, pskb_may_pull() failed, and the goto inhdr_error path was taken.
This matches the function’s epilogue: only the blocks starting from inhdr_error: are covered.
This coverage report meant that generated packets were too short to contain the iphdr structure.
syzkaller’s code coverage reports are not perfect. As the compiler can optimize and reorder the code, the mapping from basic blocks to lines might be imprecise. Moreover, only one of the lines in every basic block is marked. Nevertheless, these reports are extremely useful for evaluating the fuzzer.
Second run.
When I gave the fuzzer more time, it was able to generate a long enough packet and reach the IP header ihl and version checks.
However, it then got stuck there.
Even with code coverage guidance, syzkaller couldn’t go any deeper.
As I expected, simply taking random bytes was not good enough to generate packets that would pass kernel sanity checks.
KCOV’s comparison operands collection might have helped with the ihl and version checks, but the fuzzer would get stuck further in the code anyway.
Tip.
There is another way to figure out why syzkaller gets blocked.
You can take the program that reaches a particular basic block but fails to go further, execute it manually, and observe what happens within the kernel.
My favorite way of doing the latter is adding a bunch of pr_err() into the kernel code.
But you can use perf-tools or your favorite debugger instead.
🗄 Describing packet structure
To help the fuzzer to go deeper, I started writing proper syzlang descriptions for network packets.
I only knew the basics about a few network protocols, so I had to read a lot of RFCs and try to replicate packet structures from them.
RFCs are documents published by Internet Engineering Task Force that contain technical specifications for the Internet protocols: IPv4, IPv6, TCP, UDP, and many others.
Writing descriptions took many iterations of trial and error. I won’t try to recall every step. Instead, let me walk you through the final result.

Ethernet.
First, I changed the second argument of syz_emit_ethernet to the eth_packet structure that describes an Ethernet frame:
syz_emit_ethernet(len len[packet], packet ptr[in, eth_packet])
An Ethernet frame contains destination and source MAC addresses, an optional VLAN tag, an EtherType, which indicates the protocol encapsulated in the payload, and a payload with higher-level protocol data.
eth_packet includes the first few fields of an Ethernet frame and the eth2_packet payload:
eth_packet {
dst_mac mac_addr
src_mac mac_addr
vtag optional[vlan_tag]
payload eth2_packet
} [packed]
The [packed] annotation means the structure fields are laid out without padding.
Without this annotation, syzkaller follows the padding rules of C structures.
MAC.
If the destination MAC address in the packet were generated randomly, the created TUN/TAP interface would discard this packet.
To avoid this, I defined mac_addr as a union that includes an option with the LOCAL_MAC address assigned to the interface:
type mac_addr_t[LAST] {
a0 array[const[0xaa, int8], 5]
a1 LAST
} [packed]
mac_addr [
# This matches LOCAL_MAC in executor/common_linux.h:
local mac_addr_t[const[0xaa, int8]]
# remote, random, empty, broadcast, ...
]
A few options are hidden for consiceness. Click the switch to see them.
mac_addr_t[LAST] is a template. When used like mac_addr_t[const[0xaa, int8]], syzlang compiler creates an instance of mac_addr_t structure with LAST replaced with const[0xaa, int8].
This instance is then used in place of mac_addr_t[LAST].
Question.
How was the fuzzer previously able to reach the IP header checks in ip_rcv_core() with packets consisting of random bytes?
Did it guess the LOCAL_MAC address of the TUN/TAP interface?
Answer.
It generated a multicast MAC address.
This was not hard: the fuzzer only had to use 1 in the least-significant bit of the first octet of the MAC address.
The skb was then marked as PACKET_MULTICAST and thus didn’t get immediately dropped by ip_rcv_core().
Question.
How was the fuzzer previously able to reach the IP header checks in ip_rcv_core() with packets consisting of random bytes?
Did it guess the LOCAL_MAC address of the TUN/TAP interface?
The answer is hidden. Click the switch to see it.
More Ethernet.
The second part of an Ethernet frame eth2_packet includes the EtherType and the frame of a higher-level protocol like ARP or IPv4:
eth2_packet [
arp eth2_packet_t[ETH_P_ARP, arp_packet]
ipv4 eth2_packet_t[ETH_P_IP, ipv4_packet]
# ...
] [varlen]
type eth2_packet_t[TYPE, PAYLOAD] {
etype const[TYPE, int16be]
payload PAYLOAD
} [packed]
The [varlen] annotation means the union’s size corresponds to the chosen option in a generated program.
Without this annotation, the union’s size matches the size of the largest option, just like with a C union.
IPv4. An IPv4 packet encapsulates a TCP, UDP, or another payload type:
ipv4_packet [
tcp ipv4_packet_t[const[IPPROTO_TCP, int8], tcp_packet]
udp ipv4_packet_t[const[IPPROTO_UDP, int8], udp_packet]
# ...
] [varlen]
Here, ipv4_packet_t is a template of a structure that includes an IPv4 header and a higher-level payload:
type ipv4_packet_t[PROTO, PAYLOAD] {
header ipv4_header[PROTO]
payload PAYLOAD
} [packed]
type ipv4_header[PROTO] {
# ...
protocol PROTO
src_ip ipv4_addr
dst_ip ipv4_addr
# ...
} [packed]
TCP. Finally, a TCP packet consists of a header and a user-level protocol data represented as an array of random bytes:
tcp_packet {
header tcp_header
payload tcp_payload
} [packed]
tcp_header {
src_port sock_port
dst_port sock_port
# ...
} [packed]
tcp_payload {
payload array[int8]
} [packed]
More. These are only short snippets of the 1600 lines of syzlang descriptions for network protocols.
These descriptions were subsequently improved and refactored by Dmitry Vyukov, the original syzkaller’s author.
As I was writing these descriptions, I encountered cases where syzlang was not expressive enough. In a few cases, I extended syzlang with new features; I’ll mention this in the next sections. In other cases, I had to leave the descriptions imprecise, relying on the coverage guidance.
A few times, I noticed that the kernel doesn’t follow the RFCs precisely and skips certain features. In such cases, I studied the kernel code and tried to decipher which parts of a particular RFC it amends. I then adjusted descriptions to target the code. My goal wasn’t to make descriptions conform to the theoretical specifications from the RFCs. Instead, I wanted to make the fuzzer good at covering the Linux kernel code. When fuzzing, the targeted code is the ultimate source of truth.
🔍 Inspecting coverage #2
As I was adding descriptions, I was frequently checking the fuzzer’s coverage report.
When I added basic descriptions for IP packets, I noticed that the fuzzer was still getting blocked in ip_rcv_core():


In the report, I could see that __IP_ADD_STATS() was covered, and ntohs() was not.
Thus, the function aborted between these two calls.
This could happen either via goto inhdr_error or via goto csum_error.
Looking at the function’s epilogue, I could see that the block at csum_error: was covered.
Thus, the conclusion was: that the checksum check failed.
That made sense.
When I was writing the first draft of packet descriptions, I just used a dummy int16 value for the checksum field of IPv4 packets:
type ipv4_header[PROTO] {
# ...
csum int16
# ...
} [packed]
This obviously didn’t work: generated packets had to contain a correct checksum.
🏷 Dealing with checksums
Checksums are a bane of fuzzers. Generating correct values for them is impossible when relying only on code coverage. There’s not enough guidance. Thus, I needed to somehow deal with them.
Remove. I could remove checksum checks from the kernel or hide them under a configuration option. But this kind of change would be unlikely to be accepted into the mainline. And keeping a local kernel change would be a burden.
Calculate. Another solution was to calculate and embed the checksum when syzkaller was generating a packet. And this was the approach I decided to take.
As I was working on the packet descriptions, I encountered two types of checksums.
IPv4 checksum. The first one is the Internet Checksum, which is used for IPv4 headers. It’s calculated as:
| « | The checksum field is the 16-bit one’s complement of the one’s complement sum of all 16-bit words in the header. For purposes of computing the checksum, the value of the checksum field is zero. |
|---|---|
| RFC 791: INTERNET PROTOCOL |
TCP checksum. The other one is the pseudo-header checksum, which is used in higher-level protocols like TCP. Its computation process is more complicated.

Computing this checksum requires composing a pseudo-header filled in with data from the IPv4 header and the TCP segment length. The checksum is then calculated over all the pseudo-header, the TCP header, and the TCP payload:
Like with IPv4, for purposes of computing the checksum, the value of the checksum field is zero.
Integrating checksums.
Long story short, in a series of pull requests, I added syzlang support for both checksum types.
The changes made syzkaller’s program generator calculate and embed checksums as indicated by a newly added csum type:
type ipv4_header[PROTO] {
# ...
csum csum[parent, inet, int16be]
# ...
} [packed]
tcp_header {
# ...
csum csum[tcp_packet, pseudo, IPPROTO_TCP, int16be]
# ...
} [packed]
This required changing how syzkaller fills in argument values. syzkaller used to write all structure fields one after another. Thus, it couldn’t calculate the checksum value when it got to it: some of the required fields wouldn’t be filled in yet. To deal with this, the code was changed to fill in the checksum fields last.
Besides that, syzkaller was changed to analyze the generated program before filling in the checksums. As a part of that analysis, syzkaller builds the pseudo-header required for TCP checksum calculation.
Other protocols besides TCP and IPv4 also use the added checksum type; see vnet.txt.
In syzkaller, syz-fuzzer and syz-execprog serialize generated programs into instructions for syz-executor.
These instructions tell syz-executor what values to use when filling in structures,
when to calculate checksums, and
which syscalls to call.
syz-prog2c uses a similar mechanism.
Besides checksums, I added support for
big-endian integers int16be,
bitfields int8:1,
per-process integers proc[20000, 4, int16be],
and made a few other syzlang enhancements I found to be useful for describing network packets.
Adding syzlang features is typically non-trivial and requires changes in both the Go and C parts of syzkaller.
🥳 Getting first crashes
Once I added the checksum support, the fuzzer was able to go deeper and finally started finding things!
First bug. I believe that the first bug that I found was a slab-out-of-bounds in sctp_sf_ootb that was subsequently fixed by sctp: validate chunk len before actually using it. Unfortunately, I don’t have a reproducer for this bug, so let me show you another one instead.
I also believe that the 10.0 CVSS score for the assigned CVE-2016-9555 is a mistake: this bug is unlikely to cause serious issues.
Another bug. Here’s a reproducer for a bug syzbot discovered some time later:
This reproducer relies on IPv6 support, which I’ll mention below.
syz_emit_ethernet(0xfdef, &(0x7f00000001c0)={
@local={[0xaa, 0xaa, 0xaa, 0xaa, 0xaa], 0xaa},
@dev={[0xaa, 0xaa, 0xaa, 0xaa, 0xaa]}, [], {
@ipv6={
0x86dd, {0x0, 0x6, "50a09c", 0xfdb9, 0x0, 0x0,
@remote={0xfe, 0x80, [], 0xbb}, @local={0xfe, 0x80, [], 0xaa},
{[], @udp={0x0, 0x0, 0x8}}}
}
}
}, &(0x7f0000000040))
When executed, this program caused a remote infinite loop in the XFRM policy code:
watchdog: BUG: soft lockup - CPU#1 stuck for 134s! [syz-executor738:4553]
Call Trace:
_decode_session6+0xc1d/0x14f0 net/ipv6/xfrm6_policy.c:150
__xfrm_decode_session+0x71/0x140 net/xfrm/xfrm_policy.c:2368
...
netif_receive_skb_internal+0x126/0x7b0 net/core/dev.c:4785
napi_frags_finish net/core/dev.c:5226 [inline]
napi_gro_frags+0x631/0xc40 net/core/dev.c:5299
tun_get_user+0x3168/0x4290 drivers/net/tun.c:1951
...
__x64_sys_writev+0x75/0xb0 fs/read_write.c:1109
do_syscall_64+0x1b1/0x800 arch/x86/entry/common.c:287
entry_SYSCALL_64_after_hwframe+0x49/0xbe
Click the switch to see full stack trace.
Looking at the stack trace, you can see that it originates from drivers/net/tun.c and goes all the way down to net/ipv6/xfrm6_policy.c, where the bug is triggered.
This bug was fixed by xfrm6: avoid potential infinite loop in _decode_session6().
Not a Remote Code Execution, but still, a remote Denial-of-Service.
🔎 Inspecting coverage #3
Once I implemented the checksum support and started getting the first crashes, I took another look at the coverage report. This time, I noticed an obstacle in the TCP code:


The fuzzer was getting blocked on trying to find sockets listening on ports specified in generated packets. Indeed, when a TCP packet arrives, the kernel must route it to the application listening on the specified port. If no such port is found, the packet is thrown away.
This approach to making fuzzers is called Human-in-the-Loop.
I will stop showing coverage reports now. You get the idea: after every change, I inspected the coverage and tried to find another place where the fuzzer got stuck. I then improved that part and verified that the fuzzer goes further. And so on, and so forth.
🎁 Opening a TCP socket
This solution was to let the fuzzer open and bind sockets before executing syz_emit_ethernet.
Enabling syscalls.
The cool part was that syzkaller was able to do it by itself.
As syzkaller already had descriptions for socket-related syscalls, it was enough to enable socket$inet_tcp, bind$inet, and listen in the syzkaller’s config and start fuzzing.
All syscalls were interacting with the same kernel, so it all just worked.

Success.
After a while, syzkaller was be able to chain opening a socket with sending a packet via syz_emit_ethernet:
This program was created years ago and needs adjustments to work with modern syzkaller.
# Create a socket and bind it to a port.
r0 = socket$inet_tcp(0x2, 0x1, 0x0)
bind$inet(r0, &(0x7f0000001000)={...}, 0x10)
listen(r0, 0x5)
# Send a packet to the socket.
syz_emit_ethernet(0x36, &(0x7f0000002000)={...})
Pseudo-syscall arguments are hidden for conciseness. Click the switch to see them.
I verified that this program was indeed passing the __inet_lookup_skb() check by inspecting the coverage report.
Ports.
However, generating this program took a bit more time than I expected.
The reason was that initially, I was using random int16be values for ports.
This left little chance for syzkaller to generate the same port in both bind$inet and syz_emit_ethernet.
To resolve this, I restricted the number of allowed port values:
type sock_port int16be[20000:20004]
This way, syzkaller started using only 5 different ports, so the chance of choosing the same port for multiple syscalls became higher.
A better solution would be to rely on resources.
Unfortunately, right now, resources are meant to be produced by syscalls.
And this is not the case for ports.
You could define a few fixed default values for a resource, but this would not be any better than the current sock_port definition.
Proper support for this requires extending syzkaller.
Update from 2026:
One can use the syz_create_resource pseudo-syscall now for this purpose.
This syscall turns its integer argument into a resource, whose value syzkaller can then reuse in other syscalls in the same program.
🤝 Establishing a TCP connection
Once I managed to get syzkaller to send packets to open sockets, I thought: “Wouldn’t it be cool to teach the fuzzer to fully connect to TCP sockets externally?”.
This made sense from the bug-finding perspective as well. When the fuzzer puts kernel objects into more complicated states, it has a bigger chance of triggering bugs.
TCP handshake. First, I went to refresh my knowledge of how the TCP handshake process works:

To establish a connection, the fuzzer would have to send a SYN request, then receive SYN/ACK, and finally send ACK:
-
The first SYN request would contain a sequence number. The fuzzer could use an arbitrary one.
-
The kernel would return this number back incremented by 1 as the acknowledgment number via SYN/ACK. This SYN/ACK response would also contain a sequence number generated by the kernel.
-
The last ACK request would have to include the fuzzer’s sequence number and kernel’s sequence number, the last one as the acknowledgment number. Both incremented by 1.
Sending packets was already implemented via syz_emit_ethernet, so the SYN part was done.
I needed to implement receiving SYN/ACK packets, getting the sequence numbers out of them, and reusing them in ACK packets.
New pseudo-syscall.
Extracting sequence numbers from a packet sounded like a job for another pseudo-syscall.
Thus, I implemented syz_extract_tcp_res, which receives a packet from TUN/TAP, extracts the sequence and acknowledgment numbers from it, and increments them based on the last two arguments:
The actual implementation is more complicated due to IPv6 support.
struct tcp_resources {
uint32 seq;
uint32 ack;
};
void syz_extract_tcp_res(long a0, long a1, long a2)
{
char data[1000];
size_t length = read_tun(&data[0], sizeof(data));
struct ethhdr *ethhdr = &data[0];
struct iphdr *iphdr = &data[sizeof(struct ethhdr)];
struct tcphdr *tcphdr = &data[sizeof(struct ethhdr) + iphdr->ihl * 4];
struct tcp_resources *res = (struct tcp_resources *)a0;
res->seq = htonl((ntohl(tcphdr->seq) + (uint32)a1));
res->ack = htonl((ntohl(tcphdr->ack_seq) + (uint32)a2));
}
Validity checks are hidden for conciseness. Click the switch to see them.
Technically, to establish a connection, the fuzzer only needed to increment one of the extracted numbers and only by 1. But I decided to allow for some leeway to let the fuzzer explore unusual conditions. This didn’t produce any interesting results, though, as far as I remember.
The syzlang counter-part for this pseudo-syscall is:
resource tcp_seq_num[int32]: 0x41424344
tcp_resources {
seq tcp_seq_num
ack tcp_seq_num
}
# These pseudo-syscalls read a packet from /dev/net/tun and extract TCP
# sequence and acknowledgment numbers from it. They also adds the inc
# arguments to the returned values. This way sequence numbers get incremented.
syz_extract_tcp_res(res ptr[out, tcp_resources], seq_inc int32, ack_inc int32)
syz_extract_tcp_res$synack(res ptr[out, tcp_resources],
seq_inc const[1], ack_inc const[0])
For simplicity, both sequence and acknowledgment numbers reuse the same tcp_seq_num resource.
Note that syz_extract_tcp_res returns resources via an out pointer to a struct, not via its return value.
syz_extract_tcp_res$synack is the variant intended for properly establishing a TCP connection.
It increments the received sequence number but leaves the acknowledgment number as is.
TCP header.
Initially, I had dummy int32 values used for the sequence and acknowledgment numbers in the TCP header:
tcp_header {
# ...
seq_num int32
ack_num int32
# ...
} [packed]
I updated the header to include the newly added resource:
tcp_header {
# ...
seq_num tcp_seq_num
ack_num tcp_seq_num
# ...
} [packed]
Now, syzkaller knew it could reuse resources generated by syz_extract_tcp_res in a subsequent syz_emit_ethernet.
Connection established.
Adding syz_extract_tcp_res allowed syzkaller to generate programs that set up a socket and externally connect to it:
This program is also outdated and needs adjustments.
# Create a socket and put it into the listening state.
r0 = socket$inet_tcp(0x2, 0x1, 0x0)
bind$inet(r0, &(0x7f0000001000)={...}, 0x10)
listen(r0, 0x5)
# Send a SYN request to the socket externally.
syz_emit_ethernet(0x36, &(0x7f0000002000)={...})
# Receive a SYN/ACK response externally and increment SYN number by 1.
# Ignore 0x41424344, those are defaults if extraction fails.
syz_extract_tcp_res$synack(
&(0x7f0000003000)={<r1=>0x41424344, <r2=>0x41424344}, 0x1, 0x0)
# Send an ACK to the socket externally.
# Reuse the received sequence numbers, but swap the order.
syz_emit_ethernet(0x38, &(0x7f0000004000)={..., r2, r1, ...})
# Now, the TCP hansdhake is done. Accept the connection on the socket side.
r3 = accept$inet(r0, &(0x7f0000005000)={...}, &(0x7f0000006000)=0x10)
Running this program led to an established connection as was shown by netstat:
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:20000 0.0.0.0:* LISTEN
tcp 2 0 172.20.0.170:20000 172.20.0.187:20001 ESTABLISHED
Awesome!
Note that syzkaller doesn’t know it’s supposed to call syz_extract_tcp_res after sending a SYN request via syz_emit_ethernet.
However, chaining syz_extract_tcp_res with a following syz_emit_ethernet happens naturally due to resources.
Nevertheless, the fuzzer needs some time to guess the full syscall sequence and unlock new coverage.
With UDP, establishing a connection is much simpler.
🕵 Avoiding ARP traffic
While I was trying to get the TCP connection establishment to work, I encountered a problem.
Instead of receiving a TCP SYN/ACK, syz_extract_tcp_res$synack was getting another packet and thus failing to extract the sequence numbers.
That was an ARP packet.
ARP stands for Address Resolution Protocol. When the kernel receives a packet coming from a new IP address, it needs to resolve the remote host’s physical address before responding.
Assigned IP.
I dealt with this by avoiding this unnecessary ARP traffic altogether.
I designated a certain IP address REMOTE_IPV4 as the address of the remote host and updated TUN/TAP setup code to add this address to neighbors:
This code uses the IP utility for simplicity. syzkaller uses netlink sockets instead.
#define IFACE "syz_tun"
#define LOCAL_MAC "aa:aa:aa:aa:aa:aa"
#define REMOTE_MAC "aa:aa:aa:aa:aa:bb"
#define LOCAL_IPV4 "172.20.20.170"
#define REMOTE_IPV4 "172.20.20.187"
// Assign MAC and IP addresses.
execute_command("ip link set dev %s address %s", IFACE, LOCAL_MAC);
execute_command("ip addr add %s/24 dev %s", LOCAL_IPV4, IFACE);
// Add a neighbour to avoid unnecessary ARP traffic.
execute_command("ip neigh add %s lladdr %s dev %s nud permanent",
REMOTE_IPV4, REMOTE_MAC, IFACE);
// Activate the interface.
execute_command("ip link set %s up", IFACE);
I also included REMOTE_IPV4 into the ipv4_addr union in syzlang descriptions:
type ipv4_addr_t[LAST] {
a0 const[0xac, int8] # 172
a1 const[0x14, int8] # 20
a2 const[0x14, int8] # 20
a3 LAST
} [packed]
ipv4_addr [
# These match LOCAL_IPV4 and REMOTE_IPV4 in executor/common_linux.h:
local ipv4_addr_t[const[170, int8]]
remote ipv4_addr_t[const[187, int8]]
# random, empty, loopback, ...
] [size[4]]
This way, when the kernel would receive a TCP request coming from REMOTE_IPV4, it would already know the physical address of the host and thus skip the ARP request.
When generating an IPv4 header, syzkaller chooses the remote option for the source IP address only sometimes.
The other options are allowed to be generated to explore other scenarios.
🚽 Adding IPv6 support
Without going deep into the details, I also implemented basic IPv6 support for external packet injection.
Extensions.
I expanded the TUN/TAP setup code with setting up IPv6 addresses
and I added ipv6_addr and ipv6_packet definitions to network packet descriptions.
I also extended the checksum calculation code to support IPv6-based pseudo-headers.
To avoid unwanted discovery traffic, I designated and added REMOTE_IPV6 to neighbours and to ipv6_addr.
To avoid even more excessive traffic, I made syzkaller disable IPv6 Duplicate Address Detection and Router Solicitation. However, I failed to find a way to disable IPv6 MTD.
TCP. All this allowed establishing TCP connections over IPv6:
Another outdated program that needs adjustments.
r0 = socket$inet6_tcp(0xa, 0x1, 0x0)
bind$inet6(r0, &(0x7f0000000000)={...}, 0x1c)
listen(r0, 0x5)
syz_emit_ethernet(0x4a, &(0x7f0000001000)={...})
syz_extract_tcp_res$synack(
&(0x7f0000002000)={<r1=>0x41424344, <r2=>0x41424344}, 0x1, 0x0)
syz_emit_ethernet(0x4a, &(0x7f0000003000)={..., r2, r1, ...})
r3 = accept$inet6(r0, &(0x7f0000004000)={...}, &(0x7f0000005000)=0x1c)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp6 0 0 :::20001 :::* LISTEN
tcp6 0 0 fe80::aa:20001 fe80::bb:20000 ESTABLISHED
The IPv6 support is limited; see the section with suggested improvements below.
Done. Teaching the fuzzer to establish IPv6 TCP connections was the final feature I added as a part of this research.
☝ Other notable things
syzbot integration. As all the implemented features have been integrated into syzkaller, they were picked up by syzbot. Even now, syzbot is on the lookout for new remote network bugs.
Double-sided fuzzing. syzkaller can fuzz the network from both sides: issue syscalls from userspace and send network packets externally. This led to finding a few notable bugs: when a socket was set up from userspace in an unusual way, and then a packet was sent to this socket from the outside; an example will follow.
Isolation. As syzkaller can launch multiple fuzzing processes within a single VM, they need to be isolated. This is achieved by setting up all networking, including TUN/TAP, in a separate network namespace for each fuzzing process. Coverage is isolated naturally, as KCOV collects it per process.
Packet descriptions. The shown descriptions are only a part of the 1600 lines of syzlang descriptions for network protocols. These descriptions are not perfect, and there is a lot to add and improve; see below.
Fragmentation.
There was an attempt to add support for passing fragmented packets to TUN/TAP.
However, this functionality was later disabled due to an issue with UDP packets being rejected for an unclear reason.
Nevertheless, fragmentation is why the actual definition of syz_emit_ethernet has a third argument:
syz_emit_ethernet(len len[packet], packet ptr[in, eth_packet],
frags ptr[in, vnet_fragmentation, opt])
KMSAN checks might not be fully functional. Requires investigation.
KMSAN. Alexander Potapenko integrated checks into KMSAN to discover info-leaks that happen when the kernel sends uninitialized data over the network. Unfortunately, any leaks are yet to be found.
KMSAN is Kernel Memory Sanitizer — a dynamic kernel bug detector that detects the uses of uninitialized memory.
Socket descriptions. Besides writing descriptions for network packets, I also improved the existing descriptions for socket-related syscalls. This allowed me to find a few exploitable LPE bugs: CVE-2016-9793, CVE-2017-6074, CVE-2017-1000112, and, most notably, CVE-2017-7308, which featured an article Exploiting the Linux kernel via packet sockets in the Project Zero blog.
🏆 Found bugs
Finally, let’s take look at the discovered bugs.
🥉 Bugs in TUN/TAP
Whenever you’re fuzzing the kernel via a certain kernel interface, the first artifact you’ll likely discover would be bugs in the interface itself. Even if you’re just using it to deliver a payload to a deeper-lying part of code.
Then, you will have to fix or workaround these bugs in the interface. Otherwise, the fuzzer will be choking on them without making it to the code you meant to target.
The same thing happened here. Fuzzing the kernel packet parsing code over TUN/TAP uncovered several bugs in TUN/TAP:
🥈 Remote bugs
Moving on to a more exciting part, let’s take a look at the found remote bugs. I’ll first show the list and then walk you through a few showcases.
Manual. At first, while I was figuring out the required pieces, I was running syzkaller manually and reporting bugs by hand:
A few bugs are hidden for conciseness. You know the deal with the switch.
syzbot. Once I integrated the changes into syzkaller, syzbot picked them up and started automatically reporting found bugs along with their reproducers:
Same here.
More bugs.
This is not the full list.
There are a few dozen more bugs that I didn’t include, as they are harder to understand or less representative.
To find all relevant bugs, you’ll need to scrape the syzbot dashboard, looking for bugs with tun_get_user in the stack trace and bugs with syz_emit_ethernet in reproducers.
CVEs. Many of the bugs don’t have CVE numbers assigned. For manually-found bugs, I requested CVEs for the ones that looked more interesting than a null-pointer-dereference. For syzbot bugs, no CVEs were requested. The only exception was the bug with a scary label: "GRO packet of death".
CVEs are a controversial topic when it comes to the Linux kernel.
New bugs. As you can see in the table, the bugs were mostly exhausted by the end of 2019. Improving existing packet descriptions or adding new ones will surely uncover many new issues.
🗂 Showcases
Let’s take a look at the reproducers for a few found bugs and see which added features were at play.
GUE unbounded recursion. Let’s start with a Single-Packet-Denial-of-Service similar to the XFRM bug I showed above. In the table, this bug is represented as KASAN: slab-out-of-bounds Read in tick_sched_handle, but it manifested in a dozen of different ways on syzbot.
The reproducer simply sends a single packet:
Only showing the structure here, follow the links to see all syscall arguments.
syz_emit_ethernet(0x6a, &(0x7f00000000c0)={..., @icmp={...}, ...})
The issue was a logical bug in the Generic UDP Encapsulation (GUE) code that caused an unbounded recursion, which led to overflowing the kernel stack. Fixing this bug required a series of patches for both IPv4 and IPv6.
GRO packet of death. This one I already mentioned. Reported by syzbot as KASAN: slab-out-of-bounds Read in skb_gro_receive. The reproducer is:
r0 = socket$inet(0x2, 0x2, 0x0)
bind(r0, &(0x7f0000000080)={...}, 0x7c)
setsockopt$inet_udp_int(r0, 0x11, 0x68, ...)
syz_emit_ethernet(0x2a, &(0x7f00000000c0)={..., @udp={...}, ...})
The reproducer opens and binds a UDP socket, enables Generic Receive Offload (GRO) via the UDP_GRO socket option, and sends a packet-of-death externally.
Fixed with udp: fix GRO packet of death.
Despite being labeled a “packet of death,” it’s unclear whether this particular bug can lead to a remote crash.
TCP vs BPF dead-lock. Moving on to a more complicated example: the inconsistent lock state in sk_clone_lock crash with the reproducer:
r0 = socket$inet_tcp(0x2, 0x1, 0x0)
bind$inet(r0, &(0x7f0000001000)={...}, 0x10)
listen(r0, 0x8)
syz_emit_ethernet(0x3a, &(0x7f0000002000)={..., @tcp={...}, ...})
syz_extract_tcp_res(&(0x7f0000017000)={<r1=>0x42424242, <r2=>0x42424242}, ...)
setsockopt$SO_ATTACH_FILTER(r0, 0x1, 0x1a, &(0x7f0000017000-0x10)={...}, 0x10)
syz_emit_ethernet(0x36, &(0x7f0000004000)={..., @tcp={..., r2, r1, ...}, ...})
The reproducer sets up a TCP socket, establishes an external connection to it, and, in parallel, installs a BPF filter. The bug is a dead-lock between the TCP ACK packet handler and the BPF filter. Fixed by tcp: fix possible deadlock in TCP stack vs BPF filter.
IPv6 routed hard. Another highlight is KASAN: use-after-free Read in ip6_route_me_harder with the reproducer:
r0 = socket$inet6(0xa, 0x2, 0x0)
setsockopt$IP6T_SO_SET_REPLACE(r0, ...)
r1 = socket$inet6(0xa, 0x1, 0x0)
bind$inet6(r1, &(0x7f0000000640)={...}, 0x1c)
listen(r1, 0x2)
syz_emit_ethernet(0x4a, &(0x7f0000000100)={..., @ipv6={...}, ...})
This bug showcases the IPv6 support: the reproducer adds an IPv6 netfilter rule, sets up an IPv6 TCP socket, and sends a packet to it. Adding the netfilter rule can probably be done without an additional socket, but syzkaller didn’t figure this out. The bug was fixed by netfilter: use skb_to_full_sk in ip6_route_me_harder, which was a follow-up to a related fix.
Seeing all implemented features coming together and producing crashes was very satisfying 😁
🔨 Impact
If you look closely at all these bugs, you’ll notice that none are particularly dangerous. A few remote Denial-of-Service, sure, but no obviously exploitable Remote Code Execution. Moreover, several bugs require having a socket set up in an unusual way, which is unlikely to happen in practice.
I was keeping an eye on the bugs being found, but nothing interesting was popping up. Exploiting the few found memory corruptions by themselves without an info-leak didn’t look plausible. And KMSAN didn’t find any.
I was constantly improving the fuzzer, but that didn’t make a difference in the quality of bugs being found.
I was sad 😢
Until one day…
🥇 About that RCE
I received a report about a new bug in a certain non-public kernel flavor.
Unfortunately, as this bug only affected this particular kernel, I won’t share the details. This kernel had custom network protocol extensions, and one of them contained the bug.
Bug. The bug was a linear stack-based buffer-overflow. Essentially, a packet could smash the stack with both the size and the content controlled.
Usually, linear stack-based buffer-overflows are not exploitable due to the Stack Protector. Unless the exploit manages to leak the canary and overwrite it with the same value, the Stack Protector catches the overflow and panics the kernel.
The Stack Protector is a mitigation. It puts a canary value at the top of every function’s stack frame in the function prologue and then checks it when the function returns. If the value changed, something must have corrupted the stack, and the execution thus aborts.
Suprise. However, when I turned off KASAN and tried to reproduce the issue without it, an unexpected thing happened. The Stack Protector checks didn’t work.
As it turned out, the affected kernel flavor had the Stack Protector disabled 😐 Along with a few other basic mitigations, including KASLR 😅
Thus, the exploit could use a ROP chain and do whatever. Although, the attacker would need to know the kernel binary, which is an obstacle for non-public kernels.
The bug was fairly similar to CVE-2022-0435 in TIPC that was recently exploited by @sam4k1.
Fix. Of course, the bug was immediately fixed, and all the modern mitigations were enabled.
This wasn’t the uber bug I was initially hoping for, but I was happy enough to conclude this research.
🪠 Things to improve
There are quite a few things left to be improved:
-
More protocols. As it always is with syzkaller, writing more descriptions is beneficial. In the case of network protocols, different kinds of encapsulation seem particularly juicy. There are also a few protocols like SCTP, which are not described yet. Also see the TODOs sprinkled over vnet.txt.
-
IPv6 support. IPv6 support is limited.
Most notably, the support for IPv6 Extension Headers is impaired. These headers are chained in an unusual way, and this can’t be described without extending syzlang: the
next_headerfield must specify the type of the following header. Also,syz_extract_tcp_resdoesn’t handle these headers.Another benificial change would be to disable more types of IPv6 spam to allow better isolation of syzkaller programs. This might require changes in both syzkaller and the kernel.
-
Better resources. Improving resources is somewhat implied by the previous points, but I’ll point it out specifically. Resources enable syzkaller to chain programs — they are important.
For example, proper support for SCTP would require extending syzlang to allow handling SCTP cookies as resources. And likely adding a new
syz_sctp_extract_respseudo-syscall similar tosyz_extract_tcp_res.Also, see the note at the end of the Establishing a TCP connection section.
-
Check KMSAN. As I mentioned, KMSAN failed to find any remote info-leaks. This is unusual: KMSAN found many similar problems in other subsystems. This could be explained by KMSAN not checking the network buffers properly. This should be investigated and potentially fixed.
Reading code. If you decide to dig into the code, I suggest starting with the original pull request that added external network fuzzing support. It’s concise and shows off the main parts. Note, however, that isolation is implemented differently there, without network namespaces.
After checking out the pull request, switch to reading modern syzkaller’s sources.
The key parts are initialize_netdevices() and syz_emit_ethernet() implementations and syzlang descriptions for network protocols.
Exercise. In case you decide to build on top of this work, here’s an exercise to get started. Remember the programs for establishing TCP connections that I showed? They are based on an old version of syzkaller and no longer work. The exercise is to come up with modern programs that do the same. Either generate them with fuzzing or write manually.
In the syzkaller ecosystem, such programs are called runtests. They are a great way to check that written descriptions work as expected.
Tip. When targeting a particular network protocol, restrict syzkaller to only fuzz the relevant parts: add targeted pseudo-syscall variants, comment out undesired payloads in packet descriptions, and disable mutations of constant values. Also, check out other syzkaller-related tips.
🗃 Summary

A brief summary of the things that I walked you through.
Injecting network packets. First, I explained how TUN/TAP works and how to use it to inject network packets into the kernel.
Collecting coverage. Then I showed you KCOV — a subsystem for collecting code coverage from the Linux kernel. I explained how I modified TUN/TAP code to enable KCOV to collect coverage from the network packet parsing code.
Integrating into syzkaller. After that, I explained how I integrated everything into syzkaller. Along the way, we looked into how syzkaller works, how to write syscall descriptions, and how to add pseudo-syscalls. I showed how I was making step-by-step improvements, teaching the fuzzer to go deeper and deeper into the code.
Found bugs. Finally, I listed the remote bugs I managed to find. With an RCE in a non-public kernel flavor as the cherry-on-top.
📝 Afterword
Motivation. syzkaller’s functionality for external network fuzzing has been public for a while, but I never properly wrote it up. I used to not consider this research important, as it focused on fuzzing instead of exploitation. Since then, my views have changed, and the project is still relevant. Hence, this article.
Another reason for publishing this is to inspire people to look for things beyond generic Local Privilege Escalation bugs. Don’t take me wrong: I know that finding and exploiting an LPE is both hard and exciting, and I love the work people do. But, at the same time, I’m anxious to see more research in adjacent areas like finding and exploiting remote bugs.
This post also served as a playground for me to experiment with a few things related to writing and presenting technical texts. I even implemented a custom highlighter for the snippets 😅
Research process. I wrote this article as a step-by-step story instead of only describing the result. I outlined the process I followed: how I started with a simple proof-of-concept fuzzer and then improved it part after part. This way, you can follow the challenges I faced and the approaches I took to solve them.
Of course, in reality, the research process wasn’t as straightforward as I described. But I decided to keep things structured and, in certain cases, sacrifice precision for clarity.
Research over. This research has been on the shelf for a few years, and it’s unlikely I’ll find time to continue it in the foreseeable future. There are always things to improve, but for now, I consider this project finished.
I do, however, believe that this research has more potential. I can feel that a full-blown RCE is lurking somewhere close. Maybe you will be the one to find it.
Why syzkaller. The fuzzing approach I mentioned in the article is not directly tied to syzkaller. You can definitely write a custom fuzzer that uses TUN/TAP for packet injection.
However, my goal was to integrate everything into upstream tools. This allowed going beyond a proof-of-concept fuzzer that is run only once and then forever forgotten. Up to this day, syzbot keeps fuzzing the network subsystem and reporting bugs.
This integration was the most demanding part. Making the first proof-of-concept fuzzer based on TUN/TAP was not hard. Getting the changes into both the Linux kernel and syzkaller was what took time and effort.
Even though this book is a bit outdated.
Remote exploit. If you are interested in reading about exploiting a remote network bug, I’ll once again refer you to A Guide to Kernel Exploitation: Attacking the Core — one of the two books on Linux kernel security known to me.
Also, check out the list of resources about remote exploitation that I collected.
Acknowledgements. Many thanks to Dmitry Vyukov, Eric Dumazet, and many kernel maintainers and developers who helped me while I was working on this project. I appreciate your support!
Dmitry is the original author of syzkaller, and he supervised this work. Eric tremendously helped by answering my questions about the network subsystem. He also fixed a huge portion of the bugs I reported and today holds the record as the number one bug-fixer for syzbot-reported bugs.
All in all, externally fuzzing the network subsystem was a mere stretching before taking on the task of targeting the USB stack. But that is a story for another time.
💜 Thank you for reading!
🐵 About me
I’m a security researcher and a software engineer focusing on the Linux kernel.
I contributed to several security-related Linux kernel subsystems and tools, including KASAN — a fast dynamic bug detector, syzkaller — a production-grade kernel fuzzer, and Arm Memory Tagging Extension — an exploit mitigation. I also wrote a few Linux kernel exploits for the bugs I found.
Occasionally, I’m having fun with hardware hacking, teaching, and other random stuff.
Follow me @andreyknvl on X, @andreyknvl.bsky.social on Bluesky, @xairy@infosec.exchange on Mastodon, or @xairy on LinkedIn for notifications about new articles, talks, and training sessions.